北京话口语 语料库中,所有语料用文本格式录入,共有文件108个。根据文件中说话人说话的方式,108个文件分为3类:
o 对话文件:有两个或两个以上说话人,用问答的方式说话。这种说话方式也可以称为“对白”。
o 谈话文件:有两个以上说话人,用交叉、你一言我一语的方式说话。这种说话方式也可以称为“群白”。
o 讲话文件:有一个说话人,就一定话题长篇说话,或者几个说话人轮流就一定话题做长篇发言。这样的说话方式也可以称为“独白”。
北京话口语语料库中的文件,用文本文件形式保存,并用两种形式组织起来:
一种形式,是所有文本放在一个大文件中,文件名是BsCorpus。
一种形式,是每个文本单独存放为一个文件,文件名是“H001a”或“Ha001”这样的形式。文件名中,“H”是语料库的标记,“001”是文件的序号,“a”是文件的分类代号。分类代号为“a”,是对话文件,分类代号为“b”,是谈话文件,分类代号为“c”,是讲话文件。
1.文件
所有语料用文本格式录入。
文件名以“H”打头,后面是三位数字,从001到108,代表语料文件的序号,数字后面是a、b或c,代表文件内容的分类。
2.格式
• 每行开头是“H024a0012|B:”这样的行标记。其中,“H”是语料库标记,“024”是文件编号,表示这是第24号文件中的内容,后面是小写字母表示的分类代号,这里,“a”表示这个文件分类上是a类,即对话文件,后面是表示行号的4位数字,“0012”表示这行是第24号文件的第12行。“|”是分隔符号,后面是说话人代号。
• 说话人的代号由半角A、B、C等和全角符号“:”组成的,不同的说话人用不同代号,一个语料里,有几个不同的说话人,用几个不同的代号。说话人不明或多人同时说的话,说话人用“X”代表。
• 一个说话人的话一行放不下,放在多行上。说话人改变,另起一行。
• 一个说话人话说完了,一定有结束的标点(。!或?),一个说话人话没说完又不说了,用省略号(……)表示;一个说话人话没说完但被另外的说话人打断,用破折号(——)表示。
• 录音听不清楚的地方时用“……”表示。一个说话人说话中的“……”插在他的话中,不同说话人之间的“……”单独占一行。
• 一个说话人的话中大停顿、迟疑、反复、不连贯的地方,用顿号“、”表示。
3.字符
• 汉语的内容全部用全角字符,包括汉字和中文标点。
• 汉字
• 汉字使用GB字符集中的汉字,GB字符集里没有的汉字可使用GBK里的汉字;异体字中,尽量选择GB字符集里的正体。拟声词,选择GB字符集里的字表示,如果没有,用同音字表示。
• 北京话里的方言用字,根据徐世荣的《北京土语辞典》(北京出版社,1990年4月一版)、宋孝才的《北京话语词汇释》(北京语言出版社,1987年9月一版),同一个词的用字要统一,例如,“nar4har0” 写作“那儿哈儿”。
• 北京话特有的方言词语,有音无字的方言词语,塔布词语,用汉语拼音记录。具体方法见下面。
• 北京话与普通话用字相同的而念法不同的词语而《现代汉语词典》已经收录的,不注北京话方言读音;如果是一个北京话特有的方言词语,按上述方法处理。
• 汉语以外的内容,如外国人名、外语词语使用半角字母和标点。
• 汉语拼音,使用半角字符。汉语拼音的声调用1、2、3、4、0表示,分别代表第一、二、三、四、轻声,ü用v代替。儿化,汉字后用“儿”表示。汉语拼音中,儿化词用字母“r”表示,加在音节后面、声调符号(1、2、3、4、0)前面的。
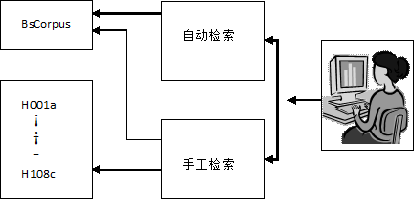
为了便于北京话口语语料库的使用,我们编制了配合北京话口语语料库使用的检索软件。这个软件完全是Windows操作环境下运行的窗口风格的软件,有操作方便的菜单和工具条。这个软件为使用者提供了两种检索方法:自动检索和手工检索。
自动检索,是由程序按使用者设定的条件和“目标”在北京话口语语料库对相应的“对象”进行检索;手工检索,是在窗口中打开北京话口语语料库文件,由使用者在查看语料库文本时选择文本中的一定内容,并复制到另外的窗口中。
两种检索方法,各有各的用途。对检索的目标比较明确时,使用自动检索很方便,对检索目标不是很明确时,使用手工检索也许更有效。手工检索,既可以在北京话口语语料库全部语料中浏览、查找、检索,也可以在某一单篇预料中浏览、查找。
为了配合检索软件的使用,北京话口语语料库中的文本,用两种形式组织起来:一种形式是所有文本放在一个大文件中;一种形式,是每个文本单独存放为一个文件。存放有所有文本的文件,用于对语料库的自动检索和在全部语料文本的进行人工检索;存放单独文本的文件,用于对语料库单篇文本的人工检索。
使用北京话口语语料库时,使用者不必直接面对这些文件,而是通过检索软件与这些文件打交道。这样,可以避免使用者频繁打开、关闭语料库文件的麻烦,同时,也可以更好保护语料库的内容。这可以示意如下。